The Interactive Mobile App Review Toolkit (IMART):
A clinical practice-oriented system
KEYWORDS
digital health; healthcare; apps; reviews; standards; app attributes; clinical practice; thesaurus; IMART
AUTHORS
- Marlene M. Maheu, PhD, Executive Director, TeleMental Health Institute, Inc., Arizona State University; 5173 Waring Road #124, San Diego CA 92120; mmaheu at telehealth.org
- Viola Nicolucci, MA, Health Psychologist, Psychotherapist, Ordine degli Psicologi del Piemonte, Network Professionale di Alessandria, Alessandria, Italy; violanicolucci at gmail.com
- Myron L. Pulier, MD, DABPN(P), Clinical Associate Professor of Psychiatry, Rutgers New Jersey Medical School, Newark; pulierml at gmail.com
- Karen M. Wall, EdD, RN-BC, MFT, Registered Intern, US Army Retired/Dementia Care Coordinator, VA Palo Alto Health Care System—Extended Care Service; Community Living Center, 195 Willow Rd/331-C152, Menlo Park CA 94025; logos68540 at gmail.com
- Tami J. Frye, PhD, LMSW, GC-C, Contributing Faculty, College of Social and Behavioral Sciences, Walden University, 100 Washington Avenue, S. #900, Minneapolis, MN 55401; tami.frye at waldenu.edu
- Eva Hudlicka, PhD, MSW, LICSW, Principal Scientist, Psychometrix Associates; Psychotherapist, Therapy21st; Visiting Lecturer, School of Information and Computer Sciences, University of Massachusetts-Amherst; 140 Governors Dr., Amherst, MA 01003; hudlicka at cs.umass.edu
CONFLICTS
- Dr. Maheu is the executive director of the TeleMental Health Institute, Inc.
- Dr. Pulier is a member of the Scientific Advisory Board and faculty at the TeleMental Health Institute.
COPYRIGHT NOTICE
This article is copyright © 2017 by Springer International Publishing. It is a "pre-print" version, the accepted manuscript of an article to be published in Volume 1 Number 1 of The Journal of Technology in Behavioral Science. The final publication is available at Springer via http://dx.doi.org/10.1007/s41347-016-0005-z
INTRODUCTION
The authors are developing the Interactive Mobile App Review Toolkit (IMART)
to overcome major obstacles that are preventing mobile healthcare apps from becoming part of routine clinical practice. Among such barriers are the challenges of finding a high quality healthcare app among the defective ones flooding the market, the inability of current review methods to address the vast number of apps and other health information technology products being offered [1], the uncertain validity of most app reviews and recommendations [2, 3], and the difficulty in discerning from a review whether an app is appropriate for particular patients and likely to fit into a clinician’s practice approach and workflow [4]. Because efficacy studies are sparse, guidance from a curated collection of expert reviews is crucial in selecting apps to use or recommend along the lines of whatever practice model suits the immediate needs of a client or patient [5].
In addition to the review toolkit itself, the authors are developing a Digital Health Thesaurus
of review standards to provide criteria for assessing products being reviewed. As distinguished from a simple listing of criteria, a thesaurus is a controlled vocabulary
of concepts that avoids semantic ambiguity and aids precision and recall of the concepts, relates the concepts by arranging them into various hierarchies and contains rules for how to use the material, such as for search and for conceptually organized display [6].
Together, IMART and the Thesaurus will enable reviewers to make high quality app reviews readily available in a searchable Digital Health Review Library
(a part of the toolkit) that will spare clinicians from having to forage for reviews of apps that seem acceptable for their clients/patients and for their practices. Well-designed review criteria will help reviewers point to the efficacy to be expected of the apps, their risks, and costs. Such a systematic approach would allow the responsible and informed clinician to try out the most promising candidates before making recommendations to patients.
PROBLEMS WITH EXISTING APPS AND APP REVIEWS
The pipeline
leading healthcare apps from creation to inclusion in clinical practices is deficient from the start as there are no quality standards for key aspects of the apps. Indeed systematic reviews of apps for particular issues may report finding crippling defects in every app considered [7-9]. Even what initially seem the best commercially available healthcare apps may turn out to be almost unusable by patients [10].
The clinically relevant features of nearly all available healthcare apps are not well grounded in science and the quality of their therapeutic interventions and other features may be poor, but this may not be communicated in reviews. Currently available reviews of mHealth apps have largely focused on personal impressions, rather than evidence-based, unbiased assessments of clinical performance and data security
[3]. On diligent scrutiny many healthcare apps fail reasonable safety criteria [9, 11]. Torous, Chan, Yellowlees, & Borland described how an unregulated free market exists in which many apps are being developed that are of uncertain quality and efficacy
[12].
Many clinicians support the view that therapeutic health interventions should be guided by science, not by art
(as articulated by L’Abate [13], the line between art and charlatanry is very thin indeed
); yet professional organizations alone are unlikely to take concrete steps to limit and prohibit irresponsible and sometimes reprehensible practices
[13]. Although the president of the American Medical Association has severely criticized many existing first generation
apps [14, 15], no professional organization offers guidelines [16]. Governmental regulation of apps also is lacking with respect to apps that are not directly connected to regulated medical equipment [17-19]. The current state of affairs may exist in part because research to indicate how best to regulate digital healthcare in general is lacking [20, 21] and because of hesitation to inhibit progress in the rapidly developing app industry [22, 23]. The result then is succinctly summarized by Wicks & Chiauzzi: there are few centralized gatekeepers between app developers and end-users, no systematic surveillance of harms, and little power for enforcement
[24]. The current authors therefore are attempting to advance the position taken by Pereira-Azevedo et al. [25] that a credible process for certifying apps could improve the safety and quality of apps that are seriously considered by clinicians.
CURRENT SEARCH MECHANISMS
A new healthcare app must be discoverable
to be adopted into clinical practice [26] but well-stocked easy-to-use repositories of such apps do not yet exist. For instance, the search feature in major online app outlets—the iOS App Store (https://itunes.apple.com/us/genre/ios/id36), Google Play (https://play.google.com/store/apps), Windows Phone Store (https://www.microsoft.com/en-us/store/apps/windows-phone/) and BlackBerry World (https://appworld.blackberry.com/webstore/)—retrieve a large and unwieldy set of apps in response to general search terms [27], contributing to a clinician’s healthapp overload
[28, 29] from the over 165,000 health apps publicly available [4]. The descriptions, popularity statistics and user reviews posted for each app retrieved on store
outlets may be all that a clinician takes time to consider, but these data are insufficient to clarify which apps are worth looking into and certainly are not a reliable basis for bringing an app into clinical use [9, 11, 30-32]. Improving search functionality alone has little prospect of incremental benefit for clinicians, for patients, for carers or for the general consumer [33].
The issue of privacy safeguards is insufficiently addressed in search results. Over one-third of the most-downloaded health and fitness apps do not present their privacy policy on their app store listing page, requiring installation of the app and release of personal information to reveal the policy... and 30% of such apps turn out not to have a privacy policy [34]. Many apps offer privacy policies that do not protect privacy, fail to disclose that they share clinical information with outside parties, and do not implement even rudimentary security safeguards [35-38]. Installing certain apps could result in massive clandestine leakage of information about the user [39]. Information acquired from app users, particularly data related to health and fitness, is commercially highly desirable, and selling it is common practice among app purveyors [40, 41]. Because many patients are concerned about their personal health information remaining confidential, when a clinician employs, endorses or is remembered by a patient or client to have tacitly given the nod to an app mentioned by either party during a session, she opens herself to liability issues should the app later be reported to be unsafe [38, 42]. At least this could impair the patient’s trust and weaken the clinician’s effectiveness, especially with patient groups particularly distrustful of hospitals, insurers, physicians and all healthcare components [43].
Before using an app with a client or patient or recommending it, a practitioner should become thoroughly familiar with its features and functionality and decide whether employing the app is likely to result in substantial improvement in a clinical issue that is important to the practitioner or to the patient [44] without burdening clinical workflow [45]. Clinicians cannot personally review each candidate app retrieved from an app store. To narrow their range of options, clinicians need an up-to-date list of apps that have been carefully selected for their quality and that are adequately described. However, of the various websites that have undertaken to offer lists of favored apps, most tend not to be curated by clinical professionals and their recommendations lack clear validity [9]. The exception may be the recently announced RANKED Health approach (http://www.rankedhealth.com/approach/), with its expert consensus reviews of a small but growing number of healthcare apps and its plan to cover digital devices as well.
It remains for expert reviews to help winnow-out poorly constructed and poorly performing apps and to focus attention on the best ones for various purposes, but existing reviews generally are not adequate for a clinician’s discovery and selection of appropriate apps. For one thing, surveys have found no uniformity in defining attributes of apps to be rated, neither for setting criteria for ratings nor for organizing low-level attributes into higher-level categories that are awarded star
ratings [46-60].
Several groups have proposed frameworks for evaluating apps, either as a set of general categories for clinicians themselves to use [16, 56] or as specific rating instruments for reviewers to apply [60]. However, these suggested topics do not take into account the perspectives and real-life challenges faced by service providers
[5]. Table 1 shows examples of app qualities that have been recommended for clinicians to inspect [16, 56], for app developers to address [61], for consumers to consider [62] and as features that are particularly user-centered [63].
- “ASPECTS” of an App [16]
- Actionable
- Secure
- Professional
- Evidence-based
- Customizable
- TranSparent
- “MAP/MAP” Dimensions [56]
- Applicability
- Validity
- Effectiveness
- Usability
- Interoperability
- Security
- Recommendations for Future Mental Health Apps [61]
- Cognitive behavioural therapy based
- Address both anxiety and low mood
- Designed for use by nonclinical populations
- Automated tailoring
- Reporting of thoughts, feelings, or behaviors
- Recommend activities
- Mental health information
- Real-time engagement
- Activities explicitly linked to specific reported mood problems
- Encourage nontechnology-based activities
- Gamification and intrinsic motivation to engage
- Log of past app use
- Reminders to engage
- Simple and intuitive interface and interactions
- Links to crisis support services
- Experimental trials to establish efficacy
- Format for Consumer-Oriented Expert Reviews [62]
- Pros
- Cons
- Description
- Ease of Use and User Experience
- User Interface
- Appropriateness of Content
- Appropriateness of Feedback
- Cognitive Challenge
- Ease of Account Management
- Scientific Basis
- Qualitative Review of Program Efficiency
- Estimate of Efficiency Relative to Similar Products
- Cost
- Notes
- More information on the product, and where to get it
- User-Centered Features for HIV Apps [63]
- Provider-patient and patient-peer communication
- Reminders
- Medication logs
- Lab reports
- Pharmacy information
- Nutrition and fitness
- Resources
- App settings (password, etc.)
- Search within the app
STAR RATING SYSTEMS
Unfortunately, while the above systems seem at first to make enough sense of the issues to be useful to an inquisitive clinician, finding disagreement in star ratings
between reviewers on the broad opinions expressed about such high-level categories as those listed in Table 1 does not amount to understanding the points of disagreement. The categories do not provide for suggestions to clinicians about incorporating an app in clinical care. They are not detailed enough to pinpoint remediable weaknesses and to offer app developers an actionable way to judge improvements in a new version of an app.
For many clinicians, guessing at the value of an app may involve only a cursory examination of the vendor’s product description and of the distribution of consumer ratings as posted at an app store. Even supplementing this impression with an expert’s star ratings leaves the clinician with little guidance for safely installing the app on his own device, familiarizing himself with it and arriving at a judgment about whether to use it with any patients.
On the other hand, if reviewers would work from a standardized and detailed schedule of attributes, reviewed according to explicit criteria, these more concrete assessments could be compared across reviewers. The overall ratings awarded to various general categories would thus be more reliable and clinicians could verify their basis. The current lack of a viable app certification system could be addressed with technology-assisted handcrafted reviews, produced with a tool that facilitates attention to the necessary level of detail, implements research-justified guidelines, and encourages a reviewer to comment in-depth about any special safety concerns or other issues raised by the app [64].
IMART AND THE DIGITAL HEALTH THESAURUS
In 2014, the TeleMental Health Institute (http://telehealth.org) recruited a team of experts, originally to improve generation of reviews of mobile behavioral healthcare apps that would be posted on its website for a general audience by extending the MAP/MAP instrument [56]. However, similar approaches, focused on rating just a handful of dimensions, came under criticism as allowing too much opportunity for subjectivity, resulting in low inter-rater reliability of key clinical measures [65].
Encouragingly, major progress towards generation of scientifically verifiable assessments was recently made by the Mobile Application Rating Scale (MARS) [60, 66]. It both clearly defines app attributes and clusters them in a validated and practical instrument that enables more-objective, multidimensional rating and comparison of mobile health apps [60, 66]. Another recent innovation is RANKED Health (http://www.rankedhealth.com/), where clinicians can discover apps reviewed as best in class
by a consensus of expert reviewers and an editor in a process resembling peer review of journal articles.
IMART GOALS
In response to progress in the field of app reviews, the authors of the current article developed a new framework for producing reviews that would also support development of apps and investigation of which aspects of apps achieve specific outcomes for various problems in various populations [67]. They adopted a detailed, two-pronged approach to fostering reviews. First, reviews would be grounded on a fine-grained and well-defined list of app aspects that can each be assessed objectively and rigorously. Second, the detailed aspects would be assembled into a thesaurus that defines terms unambiguously and groups them into easily understood categories that enable star ratings of app qualities relevant to clinical practice. Review readers could access the detailed scores to confirm those at-a-glance
summaries. Accommodating both detail and generalization is intended to avoid the many problems created by directly scoring high-level categories [68]. The framework would be instantiated as an online system for guiding and facilitating creation of reviews. The system would present its reviews in a curated central library where they could be discovered, aggregated and directly compared with one another along their built-in uniform dimensions. This depository would enable systematic study of the reviews, of the reviewing process and even of the reviewers themselves.
DEFINING A SET OF ATTRIBUTES
The current authors undertook a comprehensive literature search of English-language papers from 2000 to 2016 to compile a list of app attributes for reviewers to consider. They examined such app review services as offered by the Anxiety and Depression Association of America’s (ADAA) Mental Health Apps website http://www.adaa.org/finding-help/mobile-apps), iMedicalApps ), IMSHealth AppScript https://www.appscript.net/), The American Health Information Management Association (AHIMA)’s MyPHR https://www.myphr.com/Resources/mobile_PHRs.aspx), the National Health Service — UK Health Apps Library http://apps.nhs.uk/), One Mind Institute’s PsyberGuide (http://psyberguide.org/), Social Wellth http://socialwellth.com/) and the curriculum standards developed by the Centers for Disease Control and Prevention [69] as well as the behavior change taxonomy of Abraham, & Michie [70]. They also considered the mERA guidelines for reporting mobile based health interventions [86], the framework for app risk assessment proposed by [71], the Future of Privacy Forum recommendations [34], the RCP Health Informatics Unit checklist [72], the properties influencing aesthetic appraisal of user-interfaces mentioned by [73]; criteria proposed for serious games [74] and the classification of the large medical app database of the University of Texas Health Science Center at Houston [75].
On the basis of this list and their professional judgment, the authors subsequently compiled an extensive set of Attributes
of apps or app reviews to be rated. (See the Glossary below for definitions of bolded terms.) The aspiration for this collection is that Attributes not overlap and that the set be comprehensive, covering all aspects of mobile healthcare apps and reviews that could reasonably be subject to evaluation and reporting. Each Attribute is associated with a brief definition, a rating scale and an article contained in a Digital Health Standards Database
. The authors created a supplementary wiki that holds expanded explanations of the Attributes. Because this wiki can also accommodate invited scholarly discussion about an Attribute as well as user comments, the wiki is named the Digital Health Encyclopedia
.
The authors then added a requirement that the set of Attributes be organized hierarchically as a theory-driven taxonomy in a way that contributes to the reviewer’s perspective on the meaning of each Attribute. Therefore the Attributes were organized into logical Clusters
in a way cognizant of how material has been grouped in published reviews of apps and of health-related websites [46-55, 57-59, 70, 76]. Each Cluster has its rating scale and Digital Health Encyclopedia article. Clusters are further classified into Quadrants
in a theory-based manner, as explained below.
The database of Attributes, their arrangement into a taxonomy and their extended description in the Encyclopedia amount to a thesaurus [6]; hence the name Digital Health Standards Thesaurus.

A simplified mock-up of an IMART Reviewer’s Workbook data entry form for the Learnability Attribute is shown above. The reviewer alters data for both Learnability and its superordinate Usability Cluster. The links at the bottom navigate to a form for a different Attribute within the Usability Cluster. Clicking on a “breadcrumb” link at the top of the form can navigate to a data entry form for a different Cluster. The system offers guidance or editable default text in the Comment boxes.
The Usability Cluster shown in this example is one of the IMART Reviewer’s Workbook Clusters that calls for a “star rating” that could appear in the published review. In the Comment text shown for Usability, clicking on the “accessibility” link opens the associated Digital Health Encyclopedia article. The “USABILITY” and “LEARNABILITY” labels similarly link to the Encyclopedia.
THE IMART REVIEWER’S WORKBOOK
Having established a preliminary thesaurus containing Attributes and Clusters, the authors next designed the IMART Reviewer’s Workbook
, an online instrument that presents a series of interactive forms for scoring and commenting on an app’s Attributes.
A reviewer initializes a blank online Workbook instance by entering information identifying herself and a target app, then storing the new Workbook in the Digital Health Review Library as a private
review available only to the reviewer. She may then bring up an IMART Reviewer’s Workbook data entry form for some Attribute, select a score from its rating scale and enter commentary. Forms such as the one illustrated in Figure 1 are also used to assess Attribute Clusters.
PRODUCING A REVIEW
- Interactive Mobile App Review Toolkit (IMART)
- IMART Reviewer’s Workbook Resource
- Individual Workbook instances
- Data entry forms
- Review Drafting Wizard
- Digital Health Review Library
-
- Private Reviews
- Submitted Reviews (awaiting release by a moderator)
- Public Reviews
- Review narrative
- Attribute ratings and comments
- Visitor comments
- Digital Health Standards Thesaurus
- Digital Health Standards Database
- Digital Health Encyclopedia
- Articles about Standards (e.g. about app Attributes)
- Other Encyclopedia articles
IMART includes a Review Drafting Wizard
in its toolkit that automatically renders the reviewer’s ratings and comments into a compact readable Review Report. This draft acts as feedback
that reflects how the ratings might come across to someone reading the review. The reviewer is free to modify Workbook data to see how that changes the automated draft. The reviewer can edit the draft to create a final version of her Review Report in the Digital Health Review Library, where a moderator may then agree to make the review public
. Library visitors can search among all public reviews produced with the IMART Reviewer’s Workbook and can submit comments that will be available to all visitors. The Library also holds the detailed ratings and comments reviewers have made in their Workbooks and makes these data available to Library visitors as a supplement to the Review Reports.
Thus IMART has three main components: the IMART Reviewer’s Workbook, the Review Drafting Wizard and the Digital Health Review Library. The Digital Health Standards Thesaurus is composed of the Digital Health Standards Database and the Digital Health Encyclopedia (Table 2). IMART depends on the Thesaurus for its review criteria and can supply data based on the experience of reviewers and comments in the Library for upgrading the Standards and Encyclopedia articles.

Having chosen or been assigned an app, the reviewer copies information from the vendor into the Reviewer’s Workbook. She then downloads, installs and starts using the app while noting her observations in the Reviewer’s Workbook. The reviewer cycles among these activities, perhaps turning to already-published reviews, consumer comments and other sources of information. When the reviewer feels she has annotated enough Reviewer’s Workbook Attributes and Clusters, she activates the Workbook’s Review Drafting Wizard and edits its suggested review presentation. The reviewer may then amend her entries or rate additional Attributes. A review may then be submitted to a Digital Health Review Library volunteer moderator for conversion of its status from “private” to “public”.
An instance of the IMART Reviewer’s Workbook accepts and organizes a reviewer’s detailed and systematic observations by drawing upon the Digital Health Standards Database for definitions of Attributes and rating scales. The Review Drafting Wizard of the Reviewer’s Workbook helps the reviewer create a readable presentation. The reviewer could add audio narrative, screenshots of the app and video demonstrations into the final version of her review.
The reviewer’s workflow is illustrated in Figure 2.
ATTRIBUTE TAXONOMY
The authors anticipate that a theory-based clustering of Attributes in both the Digital Health Encyclopedia and the IMART Reviewer’s Workbook can provide important context that enhances the understanding of reviewers and readers. Assessment of an app on the Cluster level is not simply a matter of estimating the central tendency of its underlying Attribute scores. Instead, a vertically complex
task is involved [77, 78], requiring recursive consideration of Cluster qualities and underlying Attribute qualities and adding information for a Cluster that does not exist on the Attribute level alone. Furthermore, evaluating Attributes and Clusters in tandem (Figure 1.) clarifies matters for the reviewer. Lastly, the hierarchical arrangement of Attributes and Clusters determines how the Review Drafting Wizard compacts raw Reviewer’s Workbook data into a terse and readable Review Report
. This raises the question of what principles to use in devising a taxonomic hierarchy.

Figure 3 diagrams the organization of a single instance of an IMART Reviewer’s Workbook. Each Attribute in the Workbook offers the reviewer its definition and a rating scale to be scored, and solicits the reviewer’s text comments. An associated article in the Digital Health Encyclopedia further clarifies what the Attribute addresses. Attributes are grouped into Clusters. Cluster scores and comments are expected to summarize information entered for their Attributes, but the reviewer is free to create and explain discrepancies. Clusters themselves are classified into Quadrants.
Reported statistical correlations between Attribute ratings may be suggestive, but have little direct application in classifying Attributes. A finding that reviewers’ values for certain app Attributes (or, by analogy, that physicians’ ratings of certain physical signs) tend to covary does not imply a lack of incremental clinical value in reporting them individually. Therefore, the authors’ decisions about how to assign Attributes to Clusters were made heuristically, based on face validity, on clinical experience, on the clustering suggested in the surveyed publications and also in accordance with L’Abate Quadrant Architecture
as described below.
Quadrants, Clusters, Attributes, rating scales and text entry fields in an IMART Reviewer’s Workbook form a hierarchy where each Cluster and Attribute has a unique name, its own rating scale and a text entry field (Figure 3).
The reviewer is invited not only to provide scores and/or descriptions for Attributes, but also to score the Clusters. The Workbook will propose as the default score for a Cluster the median score of its subordinate Attributes. If the reviewer opts to override this default, or if there is a wide variation between the subordinate Attribute ratings, the reviewer is invited to post an explanation in the text entry field for the Cluster. The reviewer may thus recognize an error, or may choose to discuss an outstanding Attribute quality in the final review presentation. For some purposes a clinician who reads the review may consider an app unacceptable if a certain Attribute rating is too low even if its overall Cluster rating is high.
Ultimately, as previously depicted in Figure 1, the reviewer’s opinions about certain of these Clusters resembles most of the bottom line
conclusions that are often expressed as a handful of star ratings
in most existing app reviews. Such compact summaries are particularly influential with consumers [79]. However, in contrast to other review systems, IMART’s top-level general ratings are justified by explicit assessment of their subordinate Attributes. These lower-level opinions are available to the visitor reading a review in the Digital Health Review Library. The reviewer’s comments that accompany the star ratings, together with the evaluations of Attributes that underlie those general conclusions constitute the type of argument
that enhances the credibility and persuasiveness of a review for a knowledgeable audience such as clinicians [80].
L'ABATE QUADRANT ARCHITECTURE
IMART groups its Clusters of Attributes in the manner suggested by the late psychology theorist Luciano L’Abate. When Dr. L’Abate joined the authors’ team in 2015, he showed how to conceptualize apps and app reviews according to scientific principles first articulated in 1962 by Thomas Kuhn, who held that theories necessarily rest on paradigms
—conventional, religious and cultural assumptions about the nature of reality that typically are taken for granted and not critically examined [81]. L’Abate and colleagues cautioned in several books that socially constructed paradigms should be regarded as separate from, yet underlying all explanatory theories; and that the paradigm should be recognized and explicitly distinguished when judging a particular theory. Furthermore, to warrant any attention, a theory should consist of models
—cause-and-effect relationships—that can be tested and falsified [82]. L’Abate wrote that the specious interchangeability
of paradigm, theory and model causes confusion that impedes unification of clinical psychology [83]. L’Abate had therefore proposed architectural principles that impose a hierarchic shape
upon the field of psychological theories, permitting more-scientific and less-prejudiced and subjective investigation of the validity of any theory.
L’Abate cautioned the authors of the present article that failure to separate and examine concepts about mobile apps that should occupy different hierarchical levels obscures some of their clinically important features. He posited that viewing apps from the perspective of a hierarchical quadrant
structure would clarify many aspects of apps that have been previously undiscussed and perhaps unrecognized. This view is in line with that of Mendelsohn [84], who took the position that the role of a critic goes beyond telling whether or even how something is good
or bad
. Rather, it is to enlarge the reader’s own critical thinking and perspective, to examine an entity and its genre from outside the box
while yet doing honor to the subject.
In line with L’Abate’s epistemological analysis the authors developed their set of Attributes and Clusters in the Reviewer’s Workbook to conform to the four divisions of what the authors now term the L’Abate Quadrant Architecture.
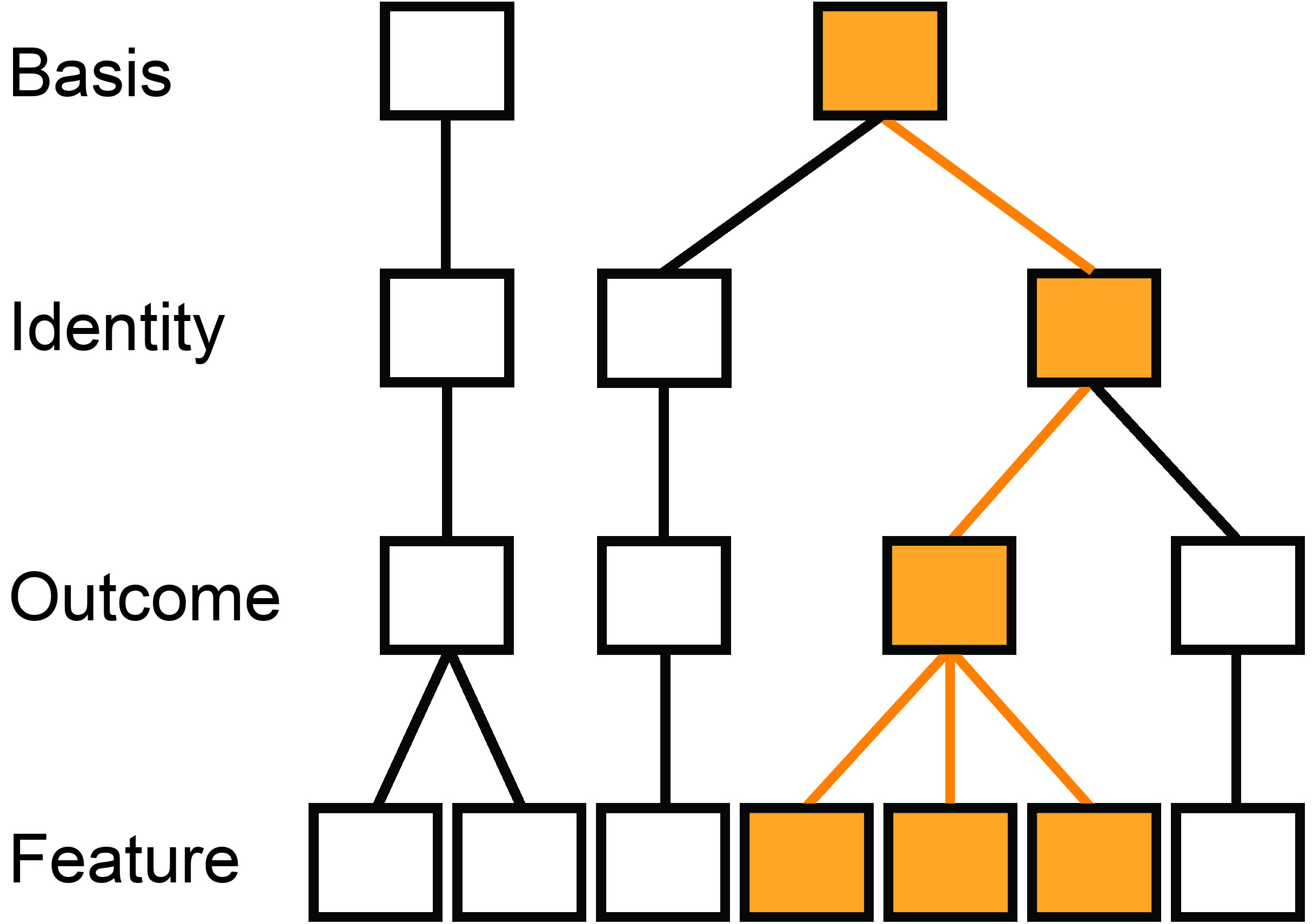
Simplified hierarchies for three app reviews are diagrammed. The reviews are demarcated on the Identity level of the L’Abate Quadrant Architecture. The review on the left stems from one Basis (such as schema therapy), but the second and third reviews are of apps that arise from another Basis (such as mindfulness). It could be that two reviewers have evaluated the same app, or that the second and third reviews are of different apps. One of the two Outcomes shown for the third identified review is depicted in color. That Outcome is shown as being influenced by three Features of the third app. For clarity, only one Feature is shown for the other Outcome that is described in the third review. Each box contains its own hierarchies of Attributes, their Clusters and their individual ratings and reviewer’s comments as depicted in Figure 3.
The Basis Quadrant
is the root of the hierarchy proposed by L’Abate. From the viewpoint of a patient and clinician, the promise of any healthcare or self-care app is to provide benefit for some problem or aspiration in accord with some professional school of thought or some common and tacit belief about human functioning, particularly about motivation and change in attitudes and behavior. Before inquiring about an app’s safety, effectiveness and efficiency a clinician would ask what the app is supposed to accomplish and along what theoretical lines: Why consider this app in the first place? What is it for? What is its clinical strategy?
Answers to these questions are unavailable in most existing reviews, as they focus on descriptions of shortcomings in their generalized ratings of broad categories. The only actionable outcome of reading a negative review is to avoid using the app. The pivotal difference from such approaches that is offered by the IMART Reviewer’s Workbook is the consideration given to describing and tagging a reviewed app as to its clinical purpose. More specifically, the Reviewer’s Workbook calls for the reviewer to communicate how the goals of the app relate to the theoretical psychological assumptions behind the app’s approach, and how well it cleaves to whichever theoretic principles it claims to follow. The IMART Workbook therefore positions the Clusters and their Attributes relevant to these questions in the root of its hierarchy, the Basis Quadrant, which corresponds to L’Abate’s original Paradigm
level [83].
The following example aims to clarify the distinctions between the hierarchic levels. Suppose that a clinician is seeking an app for a patient who lives with agoraphobia. It would be generally understood by clinicians that an app designed to implement cognitive behavioral therapy (CBT) principles differs from one designed with a mindfulness perspective. In the former CBT case, the user might be asked to document times, situations, thoughts and behaviors, at the very least. In the latter mindfulness case, users may be asked to describe something unusual or emotionally moving in their worlds. The assumption in the CBT app would be that identifying times, situations, thoughts and behaviors would decrease the undesired behavior. In the latter mindfulness app, the underlying assumption would be that increased awareness itself would generalize into reduced rumination and worry. Yet another psychological approach may rely on entertainment and distraction to break up a self-sustaining spell of worrying. The Reviewer’s Workbook would call upon the reviewer to rate and describe such theoretically relevant characteristics of an app in the Basis Quadrant (Figure 4.)

L’Abate’s four-level hierarchy may alternatively be viewed as projected onto a plane to form four “Quadrants” that are positioned along two orthogonal continua, namely Abstraction–Concreteness and Generality–Specificity. The Basis Quadrant contains a reviewer’s descriptions of those app Attributes that concern the app’s purpose, the kind of benefits an app promises to bring and the psychological concept of how this will come about. The Identity Quadrant holds concrete detail identifying which app is under review and who the reviewer is along with notes about the review process itself. The Outcome Attributes are for rating the impact the reviewer expects users of the app to experience and how well the app’s promise is likely to be fulfilled. The reviewer rates and describes the technicalities, as the Features of the app. (After L’Abate [83].)
Because many apps may strive to work according to a particular Basis, the immediately subordinate Identity
level specifies which app is being reviewed. The Clusters situated at the Identity hierarchic level concretely contain the name and version of the app under review as well as information about the developer, the reviewer’s qualifications and the review process (e.g., span of time across which the app was tried). In short, the Basis addresses for what purpose a set of apps might be considered and under which assumptions or psychological theory it is expected to work (why
and how
), while the Identity addresses which
app is under review and by whom (Figure 5).
Subordinate to the Identity level is the Outcome
level, which contains Clusters of Attributes that describe how well
the app keeps its promise to benefit the patient and to fit the clinician’s professional orientation and workflow (Figures 4 and 5).
Attributes at the Feature
level are subordinate to their Outcomes since each Outcome is produced by one or more program features of the app. Features are a matter of with what
the app is composed concretely, its nuts and bolts. Outcomes and Features, being relatively specific may more readily be judged against quality criteria using ordinal scales. On the other hand, the Attributes in the Basis and Identity levels are more general, so that most are rated as present or absent or are simply named or described.
To clarify matters more visually, in addition to their hierarchical arrangement, these four Quadrant levels may be depicted as lying on two axes: abstract–concrete and generality–specificity (Figure 5). Both the hierarchical organization and the two organizing dimensions were suggested by Professor L’Abate as adaptations of his Quadrant
scheme for psychological theories and their paradigms [83].
DISCUSSION
Listing app Attributes, and their Clusters, arranging them in a hierarchy, imposing further organization in accordance with L’Abate Quadrant Architecture, and defining Attributes in the Digital Health Encyclopedia amounts to a thesaurus [85] with multilingual potential that can be expanded to cover many aspects of digital health beyond apps, websites and sensor apparatus. The authors therefore refer to the combination of the Digital Health Standards Database and the Digital Health Encyclopedia as the Digital Health Thesaurus
.
Rearrangement, reorganization and refinement of the Digital Health Thesaurus made as reviews are produced and data accumulate would be automatically reflected in subsequent versions of the IMART Reviewer’s Workbook, as the Workbook is directly driven by the Digital Health Standards Database. The fine divisions of assessable aspects of apps and of reviews implemented in Digital Health Standards Database and the definitions and discussion contained in the Digital Health Encyclopedia could assist with designing new apps and with judging whether a proposal for an app or other digital health product should receive agency or foundation funding or venture capital investment.
Certification of an ample and diverse set of apps for clinical use and keeping up with the many innovations, though currently impractical [1], could be accomplished with reviews efficiently produced with the IMART online resources. The Digital Health Standards Thesaurus can also support creation of a list of core competencies needed to review apps adequately. Certainly, a reviewer should be aware of relevant individual components of an app, of how they work to produce their effects and of their basic assumptions and should be able to gauge how the an app would be clinically applicable, sufficiently safe for patients and therapeutically beneficial. This suggests a need for training and guidance, where a reviewer becomes able to address every Attribute, even if experience later justifies judicious shortcuts and knowing what to skim past. Reviewers can be supervised and graded as they use IMART Reviewer’s Workbooks to review a benchmark app. The list of competencies can be expanded into a curriculum and a test for reviewers leading to a certificate of completion of training.
Public access to a reviewer’s entries in the Workbook that led to her published review would help readers gain deeper insight into an app and perhaps assist them in making their own assessments of both the review and of the app itself. A clinician who takes a deep dive into a reviewer’s Workbook entries about an app or who opens a new IMART Reviewer’s Workbook and composes his own review is likely to understand the app better and to become able to use the app more effectively with his patients.
IMART will be available to anyone who provides verifiable personal identification. Such registered users could develop their own reviews restricted to personal viewing. Reviews by specifically qualified experts will be considered by moderators for being made public in the Digital Health Review Library. All registered visitors could append user comments to those reviews and to Digital Health Encyclopedia articles. Accumulated testimonials by clinicians would amount to post-marketing experience
and would add to an app’s evidence basis. Such information could help third party payers decide about adding an app to their formulary
in connection with pre-authorization of reimbursement for a clinician’s inclusion of the app in a course of treatment [86].
The IMART framework flexibly accommodates reviews of various kinds of mobile health app and other digital health and welfare products, including those direct-to-consumer products intended for use without professional guidance and reviews of such resources as those designed for access via desktop computers and those that operate independently to monitor and report on symptoms, behaviors and physiological values.
The IMART system is under active development and the authors welcome comment and collaboration from the professional health care, computer science and scientific communities.
GLOSSARY
App — mobile application, computer program running on a portable device such as a smartphone or pad.
Attribute — aspects of an App or other digital product to be rated in a review.
Basis Quadrant — the collection of Attributes related to the purposes of a digital health product and the theories behind how the goals are to be achieved.
Cluster — a collection of closely related Attributes.
Digital Health Encyclopedia — the wiki containing articles that describe Attributes in depth as well as other articles about digital healthcare and human welfare topics.
Digital Health Review Library — a public database that holds Review Reports and the IMART Reviewer’s Workbook data upon which the reports are based.
Digital Health Standards Database — the electronic storage arrangement of the IMART Reviewer’s Workbook holding definitions of Attributes and their rating scales.
Digital Health Thesaurus — a combination of Attributes and taxonomic arrangements contained in the Digital Health Standards Database together with the expanded definitions, expositions and discussions contained in the Digital Health Encyclopedia, combined with rules for using and displaying such material.
Feature Quadrant — The Quadrant that contains Attributes that concern the software and technical features of a product under review.
Identity Quadrant — The Quadrant that contains Attributes of a product being reviewed that describe what that product is, who has produced it and who is reviewing it.
IMART — The online Interactive Mobile App Review Toolkit system consisting of the Reviewer’s Workbook, the Review Drafting Wizard and the Digital Health Review Library.
IMART Reviewer’s Workbook — The authors’ online resource for generating a review of a digital health product.
L’Abate Quadrant Architecture — A conceptual framework for classifying Attributes into 4 major categories.
Outcome Quadrant — The Quadrant that contains Attributes related to the clinical effects of an app or other product being reviewed.
Quadrant — One of 4 high-level divisions of L’Abate Quadrant Architecture.
Review Drafting Wizard — A feature of the IMART Reviewer’s Workbook that automatically suggests text for a reviewer to use in writing a review.
Review Report — A concise human-readable summary of the data a reviewer has entered into an IMART Reviewer’s Workbook.
REFERENCES
- Chan, S. R., & Misra, S. (2014). Certification of mobile apps for health care. JAMA. The Journal of the American Medical Association, 312(11), 1155-1156. doi:10.1001/jama.2014.90
- Tomlinson, M., Rotheram-Borus, M. J., Swartz, L., & Tsai, A. C. (2013). Scaling up mHealth: Where is the evidence? PLoS Med, 10(2), e1001382. doi:10.1371/journal.pmed.1001382
- Powell, A. C., Landman, A. B., & Bates, D. W. (2014). In search of a few good apps. JAMA. The Journal of the American Medical Association, 311(18), 1851-1852. doi:10.1001/jama.2014.2564
- Aitken, M., & Lyle, J. (2015). Patient adoption of mHealth: Use, evidence and remaining barriers to mainstream acceptance. Parsippany, NJ: IMS Institute for Healthcare Informatics. Retrieved from http://www.imshealth.com/files/web/IMSH%20Institute/Reports/Patient%20Adoption%20of%20mHealth/IIHI_Patient_Adoption_of_mHealth.pdf
- Reynolds, J., Griffiths, K. M., Cunningham, J. A., Bennett, K., & Bennett, A. (2015). Clinical practice models for the use of e-mental health resources in primary health care by health professionals and peer workers: A conceptual framework. JMIR Mental Health, 2(1), e6. doi:10.2196/mental.4200
- Zeng, M. L. (2005). Construction of controlled vocabularies: A primer. Retrieved from http://marciazeng.slis.kent.edu/Z3919/index.htm
- Chen, J., Cade, J. E., & Allman-Farinelli, M. (2015). The most popular smartphone apps for weight loss: A quality assessment. JMIR mHealth and uHealth, 3(4), e104. doi:10.2196/mhealth.4334
- Lamichhane, D., & Armstrong, M. (2015). Systematic review of Parkinson’s disease related mobile applications. Neurology, 84(14), Supplement P7.293.
- Nicholas, J., Larsen, M. E., Proudfoot, J. G., & Christensen, H. (2015). Mobile apps for bipolar disorder: A systematic review of features and content quality. Journal of Medical Internet Research, 17(8), e198. doi:10.2196/jmir.4581
- Sarkar, U., Gourley, G. I., Lyles, C. R., Tieu, L., Clarity, C., Newmark, L., et al. (2016). Usability of commercially available mobile applications for diverse patients. Journal of General Internal Medicine, online ahead of print. doi:10.1007/s11606-016-3771-6
- Kuehnhausen, M., & Frost, V. S. (2013). Trusting smartphone apps? To install or not to install, that is the question. IEEE International Multi-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision Support (CogSIMA), San Diego, California. 30-37. doi:10.1109/CogSIMA.2013.6523820
- Torous, J. B., Chan, S. R., Yellowlees, P., & Borland, R. (2016). To use or not? Evaluating ASPECTS of smartphone apps and mobile technology for clinical care in psychiatry. Journal of Clinical Psychiatry, 77(6), e734-738. doi:10.4088/JCP.15com10619
- L’Abate, L. (2015). Review of
Science and Pseudoscience in Clinical Psychology (2nd ed.)
, Edited by Scott O. Lilienfeld, Steven J. Lynn, and Jeffrey M. Lohr. The American Journal of Family Therapy, 43(2), 210-211. doi:10.1080/01926187.2014.1002365 - AMA Wire. (2016). Deeper dive into digital snake oil: Q&A with Dr. Madara. Retrieved from http://www.ama-assn.org/ama/ama-wire/post/deeper-dive-digital-snake-oil-qa-dr-madara
- American Medical Association (Producer). (2016, June 11). 2016 AMA Annual Meeting — AMA EVP/CEO James L. Madara, MD. [Video]. Retrieved from https://www.youtube.com/watch?v=RbWgJIOWQmQ
- Chan, S., Torous, J., Hinton, L., & Yellowlees, P. (2015). Towards a framework for evaluating mobile mental health apps. Telemedicine and e-Health, 21(12), 1038-1041. doi:10.1089/tmj.2015.000
- Australian Government Department of Health. (2013). Therapeutic goods administration. Regulation of medical software and mobile medical 'apps'. Retrieved from https://www.tga.gov.au/regulation-medical-software-and-mobile-medical-apps
- U.S. Department of Health and Human Services, Food and Drug Administration. (2015). A mobile medical applications guidance for industry and food and drug administration staff. (Document 1741). Retrieved from http://www.fda.gov/downloads/medicaldevices/deviceregulationandguidance/guidancedocuments/ucm263366.pdf
- U.S. Department of Health and Human Services, Food and Drug Administration. (2016). Examples of MMAs that are NOT medical devices. Retrieved from http://www.fda.gov/MedicalDevices/DigitalHealth/MobileMedicalApplications/ucm388746.htm
- Hall, J. L., & McGraw, D. (2014). For telehealth to succeed, privacy and security risks must be identified and addressed. Health Affairs, 33(2), 216-221. doi:10.1377/hlthaff.2013.0997
- Meurk, C., Leung, J., Hall, W., Head, B. W., & Whiteford, H. (2016). Establishing and governing e-mental health care in Australia: A systematic review of challenges and a call for policy-focussed research. Journal of Medical Internet Research, 18(1), e10. doi:10.2196/jmir.4827
- Robeznieks, A. (2016). Light regulatory touch called appropriate for mobile health apps. Retrieved from http://medcitynews.com/2016/07/regulatory-touch-health-apps/
- Rowe, J. (2016). Policymakers wrestle with intricacies of regulating mobile health tech. Retrieved from http://www.himssfuturecare.com/blog/policymakers-wrestle-intricacies-regulating-mobile-health-tech
- Wicks, P., & Chiauzzi, E. (2015).
Trust but verify
—Five approaches to ensure safe medical apps. BMC Medicine, 13(1), 205. doi:10.1186/s12916-015-0451-z - Pereira-Azevedo, N., Osório, L., Cavadas, V., Fraga, A., Carrasquinho, E., Cardoso de Oliveira, E., et al. (2016). Expert involvement predicts mHealth app downloads: Multivariate regression analysis of urology apps. JMIR mHealth and uHealth, 4(3), e86. doi:10.2196/mhealth.5738
- Rogers, E. (2003). Diffusion of Innovations (5th ed.). New York, NY: Simon & Schuster.
- Shen, N., Levitan, M., Johnson, A., Bender, J. L., Hamilton-Page, M., Jadad, A. R., & Wiljer, D. (2015). Finding a depression app: A review and content analysis of the depression app marketplace. JMIR mHealth and uHealth, 3(1), e16. doi:10.2196/mhealth.3713
- van Vesen, L., Beaujean, D. J. M. A., & van Gemert-Pijnen, J. E. W. C. (2013). Why mobile healthapp overload drives us crazy, and how to restore the sanity. BMC Medical Informatics & Decision Making, 13(23), 1-5. doi:10.1186/1472-6947-1
- Farag, S., Fields, J., Pereira, E., Chyjek, K., & Chen, K. T. (2016). Identification and rating of gynecologic oncology applications using the APPLICATIONS scoring system. Telemedicine and e-Health. doi:10.1089/tmj.2016.0040
- Girardello, A., & Michahelles, F. (2010). APPAware: Which mobile applications are hot. Association for Computing Machinery 12th International Conference on Human Computer Interaction with Mobile Devices and Services, Lisbon, Portugal. 431-434. doi:10.1145/1851600.1851698
- Huguet, A., Rao, S., McGrath, P. J., Wozney, L., Wheaton, M., Conrod, J., et al. (2016). A systematic review of cognitive behavioral therapy and behavioral activation apps for depression. Plos One, 11(5), e0154248. doi:10.1371/journal.pone.0154248
- Zaidan, S., & Roehrer, E. (2016). Popular mobile phone apps for diet and weight loss: A content analysis. JMIR mHealth and uHealth, 4(3), e80. doi:10.2196/mhealth.5406
- Lorence, D. P., & Greenberg, L. (2006). The Zeitgeist of online health search. Journal of General Internal Medicine, 21(2), 134-139. doi:10.1007/s11606-006-0247-0
- FPF Mobile Apps Study. (2016). Washington, DC: Future of Privacy Forum. Retrieved from https://fpf.org/wp-content/uploads/2016/08/2016-FPF-Mobile-Apps-Study_final.pdf
- Dehling, T., Gao, F., Schneider, S., & Sunyaev, A. (2015). Exploring the far side of mobile health: Information security and privacy of mobile health apps on iOS and Android. JMIR mHealth and uHealth, 19(3), e8. doi:10.2196/mhealth.3672
- Huckvale, K., Prieto, J. T., Tilney, M., Benghozi, P., & Car, J. (2015). Unaddressed privacy risks in accredited health and wellness apps: A cross-sectional systematic assessment. BMC Medicine, 13, 214. doi:10.1186/s12916-015-0444-y
- Blenner, S. R., Köllmer, M., Rouse, A. J., Daneshvar, N., Williams, C., & Andrews, L. B. (2016). Privacy policies of android diabetes apps and sharing of health information. JAMA. the Journal of the American Medical Association, 315(10), 1051-1052. doi:10.1001/jama.2015.19426
- Armontrout, J., Torous, J., Fisher, M., Drogin, E., & Gutheil, T. (2016). Mobile mental health: Navigating new rules and regulations for digital tools. Current Psychiatry Reports, doi:10.1007/s11920-016-0726-x
- Northeastern University. (2016). Android apps can secretly track users’ whereabouts, researchers find. Retrieved from http://www.sciencedaily.com/releases/2016/08/160810141939.htm
- Glenn, T., & Monteith, S. (2014). Privacy in the digital world: Medical and health data outside of HIPAA protections. Current Psychiatry Reports, 16(11), 494. doi:10.1007/s11920-014-0494-4
- Klosowski, T. (2014). Lots of health apps are selling your data. Here’s why. Retrieved from http://lifehacker.com/lots-of-health-apps-are-selling-your-data-heres-why-1574001899
- Yang, Y. T., & Silverman, R. D. (2014). Mobile health applications: The patchwork of legal and liability issues suggests strategies to improve oversight. Health Affairs, 33(2), 222-227. doi:10.1377/hlthaff.2013.0958
- Boulware, L. E., Cooper, L. A., Ratner, L. E., LaVeist, T. A., & Powe, N. R. (2003). Race and trust in the health care system. Public Health Reports, 118(4), 358-365.
- Scher, D. L. (2013, May 7). Should you recommend health apps? Medscape Psychiatry & Mental Health. Retrieved from http://www.medscape.com/viewarticle/803503_2
- American Society for Quality. ASQ health care quality & patient experience survey: Summary report. Retrieved from http://asq.org/public/healthcare/asq-healthcare-quality-patient-summary-report.pdf
- Aladwani, A. M., & Palvia, P. C. (2002). Developing and validating an instrument for measuring user-perceived web quality. Information & Management, 39(6), 467-476. doi:10.1016/S0378-7206(01)00113-6
- Moustakis, V. S., Litos, C., Dalivigas, A., & Tsironis, L. (2004). Website quality assessment criteria. Proceedings of the Ninth International Conference on Information Quality, Cambridge, MA. Retrieved from http://mitiq.mit.edu/ICIQ/Documents/IQ%20Conference%202004/Papers/WebsiteQualityAssessmentCriteria.pdf
- Lavie, T., & Tractinsky, N. (2004). Assessing dimensions of perceived visual aesthetics of web sites. International Journal of Human-Computer Studies, 60(3), 269-298. doi:10.1016/j.ijhcs.2003.09.002
- Väätäjä, H., Koponen, T., & Roto, V. (2009). Developing practical tools for user experience evaluation: A case from mobile news journalism. European Conference on Cognitive Ergonomics: Designing Beyond the Product—Understanding Activity and User Experience in Ubiquitous Environments, Finland, Article 33. Retrieved from http://www.vtt.fi/inf/pdf/symposiums/2009/S258.pdf
- Finstad, K. (2010). The usability metric for user experience. Interacting with Computers, 22(5), 323-327. doi:10.1016/j.intcom.2010.04.004
- Vermeeren, A. P., Law, E. L., Roto, V., Obrist, M., Hoonhout, J., & Väänänen-Vainio-Mattila, K. (2010). User experience evaluation methods: Current state and development needs. NordiCHI ’10 Proceedings of the 6th Nordic Conference on Human-Computer Interaction: Extending Boundaries, 521-530. doi:10.1145/1868914.1868973
- Kay-Lambkin, F., White, A., Baker, A. L., Kavanagh, D. J., Klein, B., Proudfoot, J., et al. (2011). Assessment of function and clinical utility of alcohol and other drug web sites: An observational, qualitative study. BMC Public Health, 11(1), 277. doi:10.1186/1471-2458-11-277
- mHIMSS App Usability Work Group. (2012). Selecting a mobile app: Evaluating the usability of medical applications. Retrieved from http://s3.amazonaws.com/rdcms-himss/files/production/public/HIMSSguidetoappusabilityv1mHIMSS.pdf
- Moshagen, M., & Thielsch, M. T. (2010). Facets of visual aesthetics. International Journal of Human-Computer Studies, 68(10), 689-709. doi:10.1016/j.ijhcs.2010.05.006
- West, J. H., Hall, P. C., Hanson, C. L., Barnes, M. D., Giraud-Carrier, C., & Barrett, J. (2012). There’s an app for that: Content analysis of paid health and fitness apps. Journal of Medical Internet Research, 14(3), Je72. doi:10.2196/jmir.1977
- Maheu, M. M., Pulier, M. L., & Roy, S. (2013). Finding, evaluating, and using smartphone applications. In G. P. Koocher, J. C. Norcross, & B. A. Breene (Eds.), Psychologists’ Desk Reference (Third ed., pp. 704-708). New York: Oxford University Press.
- Wang, A., An, N., Lu, X., Chen, H., Li, C., & Levkoff, S. (2014). A classification scheme for analyzing mobile apps used to prevent and manage disease in late life. JMIR mHealth and uHealth, 2(1), e6. doi:10.2196/mhealth.2877
- BinDhim, N. F., Hawkey, A., & Trevena, L. (2015). A systematic review of quality assessment methods for smartphone health apps. Telemedicine and eHealth, 21(2), 97104. doi:10.1089/tmj.2014.0088
- Mendiola, M. F., Kalnicki, M., & Lindenauer, S. (2015). Valuable features in mobile health apps for patients and consumers: Content analysis of apps and user ratings. JMIR mHealth and uHealth, 3(2), e40. doi:10.2196/mhealth.4283
- Stoyanov, S. R., Hides, L., Kavanagh, D. J., Zelenko, O., Tjondronegoro, D., & Mani, M. (2015). Mobile app rating scale: A new tool for assessing the quality of health mobile apps. JMIR mHealth and uHealth, 3(1), e27. doi:10.2196/mhealth.3422
- Bakker, D., Kazantzis, N., Rickwood, D., & Rickard, N. (2016). Mental health smartphone apps: Review and evidence-based recommendations for future developments. JMIR Mental Health, 1(3), e7. doi:10.2196/mental.4984
- Psyberguide. Retrieved from http://www.psyberguide.org/
- Schnall, R., Mosley, J. P., Iribarren, S. J., Bakken, S., Carballo-Diéguez, A., & Brown III, W. (2015). Comparison of a user-centered design, self-management app to existing mhealth apps for persons living with HIV. JMIR mHealth and uHealth, 3(3), e91. doi:10.2196/mhealth.4882
- Powell, A. C., Landman, A. B., & Bates, D. W. (2014). Certification of mobile apps for healthcare—Reply. JAMA. The Journal of the American Medical Association, 312(11), 1156.
- Powell, A. C., Torous, J., Chan, S., Raynor, G. S., Shwarts, E., Shanahan, M., & Landman, A. B. (2016). Interrater reliability of mhealth app rating measures: Analysis of top depression and smoking cessation apps. JMIR mHealth and uHealth, 4(1), e15. doi:10.2196/mhealth.5176
- Stoyanov, S. R., Hides, L., Kavanagh, D. J., & Wilson, H. (2016). Development and validation of the user version of the mobile application rating scale (uMARS). JMIR mHealth uHealth, 4(2), e72. doi:10.2196/mhealth.5849
- Wilhide III, C., Peeples, M. M., & Anthony Kouyaté, R. C. (2016). Evidence-based mHealth chronic disease mobile app intervention design: Development of a framework. JMIR Research Protocols, 5(1), e25. doi:10.2196/resprot.4838
- Cairns, P. (2013). A commentary on short questionnaires for assessing usability. Interacting with Computers, 25(4), 312-316. doi:10.1093/iwc/iwt019
- Centers for Disease Control and Prevention. (2015). Characteristics of an effective health education curriculum. Retrieved from http://www.cdc.gov/healthyschools/sher/characteristics/index.htm
- Abraham, C., & Michie, S. (2008). A taxonomy of behavior change techniques used in interventions. Health Psychology, 27(3), 379-387. doi:10.1037/0278-6133.27.3.379
- Lewis, T. L., & Wyatt, J. C. (2014). mHealth and mobile medical apps: A framework to assess risk and promote safer use. Journal of Medical Internet Research, 16(9), e21. doi:10.2196/jmir.3133
- Wyatt, J. C., Thimbleby, H., Rastall, P., Hoogewerf, J., Wooldridge, D., & John Williams, J. (2015). What makes a good clinical app? introducing the RCP health informatics unit checklist. Clinical Medicine, 15(6), 519-521. doi:10.7861/clinmedicine.15-6-519
- Moshagen, M., & Thielsch, M. (2013). A short version of the Visual Aesthetics of Websites Inventory. Behaviour & Information Technology, 32(12), 1305-1311. doi:10.1080/0144929X.2012.694910
- Graafland, M., Dankbaar, M., Mert, A., Lagro, J., De Wit-Zuurendonk, L., Schuit, S., et al. (2014). How to systematically assess serious games applied to health care. JMIR Serious Games, 2(2), e11. doi:10.2196/games.3825
- Xu, W., & Liu, L. (2015). mHealth apps: A repository and database of mobile health apps. JMIR mHealth and uHealth, 3(1), e28. doi:10.2196/mhealth.4026
- Devine, T., Broderick, J., Harris, L. M., Wu, H., & Hilfiker, S. W. (2016). Making quality health websites a national public health priority: Toward quality standards. JMIR, 18(8), e211. doi:10.2196/jmir.5999
- Commons, M. L. (2007). Introduction to the model of hierarchical complexity. Behavioral Development Bulletin, 13(1), 1-6. doi:10.1037/h0100493
- Commons, M. L., & Pekker, A. (2007). Hierarchical complexity: A formal theory. Manuscript submitted for publication. Retrieved from http://www.tiac.net/~commons/Hierarchical%20Complexity%20-%20A%20Formal%20Theory%20(Commons%20&%20Pekker).rtf
- von Reischach, F., Dubach, E., Michahelles, F., & Schmidt, A. (2010). An evaluation of product review modalities for mobile phones. Association for Computing Machinery 12th International Conference on Human Computer Interaction with Mobile Devices and Services, Lisbon, Portugal. 199-208. doi:10.1145/1851600.1851635
- Cheung, C. M., Sia, C., & Kuan, K. K. Y. (2012). Is this review believable? A study of factors affecting the credibility of online consumer reviews from an ELM perspective. Journal of the Association for Information Systems, 13(8), 618-635. Retrieved from http://aisel.aisnet.org/jais/vol13/iss8/2
- Kuhn, T. S. (2012). The Structure of Scientific Revolutions (4th ed.). Chicago, IL: University of Chicago Press.
- Hillix, W. A., & L’Abate, L. (2012). Chapter 1. The role of paradigms in science and theory construction. In L. L’Abate (Ed.), Paradigms in Theory Construction (pp. 3-18). New York: Springer. doi:10.1007/978-1-4614-0914-4
- L’Abate, L. (2015). Chapter 6. Beyond systems thinking: Toward a unifying framework for human relationships. In L. L’Abate (Ed.), Concreteness and Specificity in Clinical Psychology. Evaluations and Interventions (pp. 73-89). Springer International Publishing. doi:10.1007/978-3-319-13284-6_6
- Mendelsohn, D. (2012-08-28). A critic’s manifesto. Retrieved from http://www.newyorker.com/books/page-turner/a-critics-manifesto
- Will, L. (2012). The ISO 25964 data model for the structure of an information retrieval thesaurus. Bulletin of the American Society for Information Science and Technology, 38(4), 48-51. doi:10.1002/bult.2012.1720380413
- Agarwal, S., LeFevre, A. E., Lee, J., L’Engle, K., Mehl, G., Sinha, C., & Labrique, A. (2016). Guidelines for reporting of health interventions using mobile phones: Mobile health (mHealth) evidence reporting and assessment (mERA) checklist. BMJ, 352, i1174. doi:10.1136/bmj.i1174